
Technology
Latent Retrieval MemoryLRM
LRM은 대화형 AI 서비스의 운영 비용을 혁신적으로 절감하는 핵심 기술입니다.
Function Calling
필요한 맥락만 선별해
토큰을 최소화합니다
함수 호출 방식을 통해 사용자와의 대화 맥락을 RAG로 자동 처리하여, 긴 대화에서도 최소한의 토큰만 사용하도록 최적화합니다. 기존 방식에서는 대화가 길어질수록 이전 맥락을 모두 유지하기 위해 토큰 사용량이 기하급수적으로 증가했지만, LRM은 필요한 맥락만 선별적으로 유지하여 비용을 대폭 절감합니다.
이는 챗봇, 모델스토어, 봇스토어, POUL 챗봇 등 모든 대화형 서비스에서 직접적인 비용 절감으로 이어져, 더 경쟁력 있는 가격 정책과 높은 수익 마진을 동시에 확보하게 합니다.
Before — 토큰 누적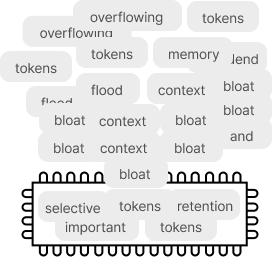
After — 선별 유지
Token Usage
대화가 길어져도 토큰은 가볍게
대화 턴이 누적될 때 토큰 사용량이 어떻게 달라지는지 비교했습니다.
Before · 기존 방식
매 턴마다 전체 맥락을 다시 전달 — 토큰 사용량이 누적되어 급증
턴 1
턴 2
턴 3
턴 4
After · LRM
필요한 맥락만 선별 유지 — 대화가 길어져도 토큰을 일정하게 절제
턴 1
턴 2
턴 3
턴 4
Cost Saving
비용 절감 효과
대량 사용자일수록 큰 효과
대량의 사용자를 보유한 서비스일수록 비용 절감 효과가 기하급수적으로 증가합니다.
가격 경쟁력 강화
직접적인 비용 절감으로 더 경쟁력 있는 가격 정책과 높은 수익 마진을 동시에 확보합니다.
고객 경험 향상
동일한 예산으로 더 많은 AI 서비스를 이용하거나, 더 저렴한 비용으로 고품질 AI 경험을 누립니다.